
This post is part four in a series about how to extend cloud-based data analysis tools – such as Google’s BigQuery ML – to handle specific econometrics requirements. Part 1 showed how to compute coefficient standard errors; Part 2 showed how to compute robust standard errors; and Part 3 showed how to perform 2SLS regressions, all in BigQuery.
The F statistic is useful when testing restrictions on linear regressions, such as whether two coefficients are equal to each other, or if including a group of variables is significant to the regression. Most regression packages report the F statistic of the overall regression as well, which tests the restriction that all the coefficients in the regression are equal to zero.
The equation for the F statistic is:
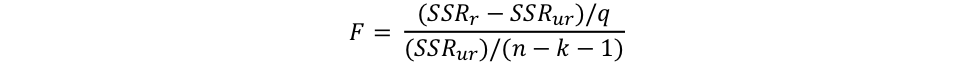
Where SSRr is the sum of square residuals of the restricted model, SSRur is the sum of square residuals of the unrestricted model, q is the number of restrictions being tested, k is the number of variables in the unrestricted model, and n is the sample size.
If the dependent variable is the same in the restricted and unrestricted models, the F statistic can also be computed as:
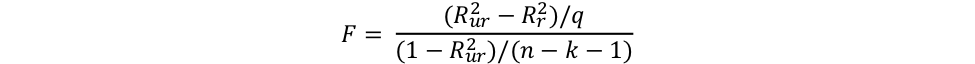
Where Rur2 is the R2 of the unrestricted model and Rr2 is the R2 of the restricted model.
Testing the overall significance of the regression requires setting all coefficients equal to zero—a regression on a constant. In this case, the R2 of the restricted model (Rr2) is also zero, thus yielding a simple formula for the F statistic of the overall regression:
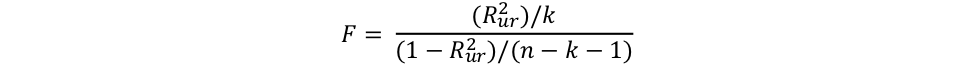
Below, I show a Python function that computes the F statistic and performs an F test on the overall regression using a BigQuery ML model. I next show a function that computes the F statistic and performs an F test on a model compared to a restricted version of the model. Finally, I show a function that creates a model and reports the F statistic for a given restriction set.
Overall Regression F Test:
First, we take as input the BigQuery dataset the model is located in, the model of interest, and the size of the data the model was generated by:
dataset = sys.argv[1]
model_name = sys.argv[2]
n = int(sys.argv[3])From there, we can generate k by counting the coefficients:
def coefficients(dataset, model_name):
coeffs = []
query = ("SELECT input, weight FROM (ML.FEATURE_INFO(MODEL `" + dataset + "." + model_name + "`) LEFT JOIN ML.WEIGHTS(MODEL `" + dataset + "." + model_name + "`) ON input = processed_input)")
query_job = client.query(query)
result = query_job.result()
for row in result:
coeffs.append(row.input)
return coeffs
coeffs = coefficients(dataset, model_name)
k = len(coeffs)Then we use ML.EVALUATE to get the R2 as we have before:
def rsquared(dataset, model):
query = ("SELECT r2_score FROM ml.EVALUATE(MODEL `" + dataset + "." + model + "`)")
query_job = client.query(query)
result = query_job.result()
for row in result:
return row.r2_scoreNext call the function from the main body:
r2 = rsquared(dataset, model_name)Then compute the F statistic numerator and denominator, divide, compute the p-value for the F statistic, and print the result:
fstatTop = r2/k
fstatBottom = (1-r2)/(n-k-1)
fstat = fstatTop/fstatBottom
pvalue = f.sf(fstat, k, (n-k-1))
print("F statistic: " + str(fstat))
print("p-value: " + str(pvalue))F Test with Restricted Model:
It is reasonably straightforward to extend the function above to get the F test to compare two models (assuming they have the same dependent variable): Add the restricted model to the inputs:
dataset = sys.argv[1]
unrestricted_model = sys.argv[2]
restricted_model = sys.argv[3]
n = int(sys.argv[4])Generate k the same way as before:
coeffs = coefficients(dataset, unrestricted_model)
k = len(coeffs)The number of restrictions q is the difference between the number of coefficients in the two models:
coeffs2 = coefficients(dataset, restricted_model)
q = k - len(coeffs2)Generate the restricted and unrestricted R2‘s with the function from above:
r2ur = rsquared(dataset, unrestricted_model)
r2r = rsquared(dataset, restricted_model)And then, same as before, compute the F statistic numerator and denominator, divide, compute the p-value for the F statistic, and print the result:
fstatTop = (r2ur - r2r)/q
fstatBottom = (1-r2ur)/(n-k-1)
fstat = fstatTop/fstatBottom
pvalue = f.sf(fstat, q, (n-k-1))
print("F statistic: " + str(fstat))
print("p-value: " + str(pvalue))Generating Restricted Models
Finally, given a model and a set of restrictions, we can generate the restricted model (in the current code, the restrictions that are possible to use are excluding a variable, setting a coefficient equal to another coefficient, and setting a coefficient equal to a specific number). Note that now we must use the sum of square residuals formula in order to allow the dependent variable to change.
First, we take in as input the dataset name, the data table name, the unrestricted model name, and the original dependent variable name, along with the size of the data and a list of the restrictions we want to impose:
dataset = sys.argv[1]
data = sys.argv[2]
unrestricted_model = sys.argv[3]
dependentVar = sys.argv[4]
restrictedDependentVar = dependentVarNext, because we’re using the sum of square residuals, we also use the coefficient function written for the robust standard error program explained in Part 2 of this series:
def coefficients(dataset, model_name):
coeffs = {}
query = ("SELECT processed_input, weight FROM ML.WEIGHTS(MODEL `" + dataset + "." + model_name + "`)")
query_job = client.query(query)
result = query_job.result()
for row in result:
coeffs[row.processed_input] = {}
coeffs[row.processed_input]['coefficient'] = row.weight
return coeffs
coeffsUnrestricted = coefficients(dataset, unrestricted_model)
coeffsToUse = list(coeffsUnrestricted.keys())
coeffsToUse.remove("__INTERCEPT__")
k = len(coeffsToUse)
n = int(sys.argv[5])The list of restrictions is divided into “exclude”, for variables we want to exclude; “set-equal” for coefficients to set equal to each other; and “specific” for coefficients equal to a specific value. We iterate through the list and calculate q as we do so:
args = sys.argv[6:]
q = 0
if (args[0] != "exclude" and args[0] != "set-equal" and args[0] != "specific"):
print("You can exclude variables, set two coefficients equal to each other, or set a coefficient to a specific number")
sys.exit()
if(args[0] == "exclude"):
for i in range(1, len(args)):
if args[i] == "set-equal" or args[i] == "specific":
args = args[i:]
break;
coeffsToUse.remove(args[i])
q += 1
if(args[0] == "set-equal"):
for i in range(1, len(args)):
if args[i] == "specific":
args = args[i:]
break;
removeCoeffs = args[i].split("=")
coeffsToUse.remove(removeCoeffs[0])
coeffsToUse.remove(removeCoeffs[1])
equalCoeffsAdd(dataset, data, removeCoeffs)
coeffsToUse.append(removeCoeffs[0] + "_" + removeCoeffs[1])
q += 1
if(args[0] == "specific"):
for arg in args[1:]:
removeCoeffs = arg.split("=")
coeffsToUse.remove(removeCoeffs[0])
resetDependentVar(dataset, data, restrictedDependentVar, removeCoeffs)
restrictedDependentVar = restrictedDependentVar + "_" + removeCoeffs[0]
q += 1As you can see, excluding variables is the easiest as we simply remove them from the list of coefficients used to generate the restricted model. Setting two coefficients equal to each other requires subtracting one from the other and replacing the two terms in the model with the difference:
def equalCoeffsAdd(dataset, data, combineCoeffs):
table_ref = client.dataset(dataset).table(data)
table = client.get_table(table_ref)
original_schema = table.schema
new_schema = original_schema[:]
new_schema.append(bigquery.SchemaField(combineCoeffs[0] + "_" + combineCoeffs[1], "FLOAT"))
table.schema = new_schema
table = client.update_table(table, ["schema"])
assert len(table.schema) == len(original_schema) + 1 == len(new_schema)
query = ("UPDATE `" + dataset + "." + data + "` SET " + combineCoeffs[0] + "_" + combineCoeffs[1] + " = " + combineCoeffs[0] + "+" + combineCoeffs[1] + " WHERE " + combineCoeffs[0] + "_" + combineCoeffs[1] + " is null")
query_job = client.query(query)
result = query_job.result()Setting a coefficient equal to a specific value requires changing the dependent variable to be the difference between the original dependent variable and the independent variable times that value:
def resetDependentVar(dataset, data, dependentVar, coeffAndScalar):
table_ref = client.dataset(dataset).table(data)
table = client.get_table(table_ref)
original_schema = table.schema
new_schema = original_schema[:]
new_schema.append(bigquery.SchemaField(dependentVar + "_" + coeffAndScalar[0], "FLOAT"))
table.schema = new_schema
table = client.update_table(table, ["schema"])
assert len(table.schema) == len(original_schema) + 1 == len(new_schema)
query = ("UPDATE `" + dataset + "." + data + "` SET " + dependentVar + "_" + coeffAndScalar[0] + " = " + dependentVar + "-" + coeffAndScalar[1] + "*" + coeffAndScalar[0] + " WHERE " + dependentVar + "_" + coeffAndScalar[0] + " is null")
query_job = client.query(query)
result = query_job.result()We add the corrected dependent variable to the list of coefficients to generate the restricted model, generate the model, set the model’s name, and store the coefficients in order to calculate the residuals:
coeffsToUse.append(restrictedDependentVar)
create_restricted_model(dataset, data, unrestricted_model, restrictedDependentVar, coeffsToUse)
restricted_model = "restricted_" + unrestricted_model
coeffsRestricted = coefficients(dataset, restricted_model)
def create_restricted_model(dataset, data, model_name, dependentVar, coeffs):
query = ("CREATE OR REPLACE MODEL `" + dataset + ".restricted_" + model_name + "` "
"OPTIONS (model_type='linear_reg', input_label_cols=['" + dependentVar + "']) AS "
"SELECT " + ", ".join(coeffs) + " FROM `" + dataset + "." + data + "` WHERE " + " is not NULL and ".join(coeffs) + " is not NULL")
query_job = client.query(query)
result = query_job.result()
def coefficients(dataset, model_name):
coeffs = {}
query = ("SELECT processed_input, weight FROM ML.WEIGHTS(MODEL `" + dataset + "." + model_name + "`)")
query_job = client.query(query)
result = query_job.result()
for row in result:
coeffs[row.processed_input] = {}
coeffs[row.processed_input]['coefficient'] = row.weight
return coeffsSince we only need to generate one set of residuals, instead of one for every variable like we did when calculating robust standard errors, we’ll use a function that combines the prediction and residuals functions from the previous blog posts:
def residuals(dataset, data, model, coeffs, dependentVar):
table_ref = client.dataset(dataset).table(data)
table = client.get_table(table_ref)
original_schema = table.schema
new_schema = original_schema[:]
new_schema.append(bigquery.SchemaField("residual_" + model, "FLOAT"))
table.schema = new_schema
table = client.update_table(table, ["schema"])
assert len(table.schema) == len(original_schema) + 1 == len(new_schema)
regression = ""
for coeff in coeffs.keys():
if coeff != "__INTERCEPT__":
regression += str(coeffs[coeff]['coefficient']) + "*" + coeff + " + "
else:
regression += str(coeffs[coeff]['coefficient']) + " + "
regression = regression[:-3]
query = ("UPDATE `" + dataset + "." + data + "` SET residual_" + model + " = " + regression + " - " + dependentVar + " WHERE residual_" + model + " is null")
query_job = client.query(query)
result = query_job.result()Run the query in the body of the program:
residuals(dataset, data, unrestricted_model, coeffsUnrestricted, dependentVar)
residuals(dataset, data, restricted_model, coeffsRestricted, restrictedDependentVar)Calculate the sum of squared residuals:
def ssr(dataset, data, model):
query = ("SELECT SUM(POW(residual_" + model + ", 2)) FROM `" + dataset + "." + data + "`")
query_job = client.query(query)
result = query_job.result()
for row in result:
return row.f0_
ssrur = ssr(dataset, data, unrestricted_model)
ssrr = ssr(dataset, data, restricted_model)Finish up by calculating the F-statistic and performing the test, as we did before:
fstatTop = (ssrr - ssrur)/q
fstatBottom = (ssrur)/(n-k-1)
fstat = fstatTop/fstatBottom
pvalue = f.sf(fstat, q, (n-k-1))
print("F statistic: " + str(fstat))
print("p-value: " + str(pvalue))I tested this code using the Stata auto dataset, running the regression mpg = weight + gear_ratio + foreign, and compare the output from Stata with the output from the code running in BigQuery. The table shows the two to be identical, baring rounding.
| F-TEST | STATA F-STAT | BIGQUERY F-STAT | STATA P-VALUE | BIGQUERY P-VALUE |
| OVERALL | 46.73 | 46.727316 | 0.0000 | 0.00000000 |
| WEIGHT=GEAR_RATIO | 0.90 | 0.9018614 | 0.3456 | 0.3455504 |
| FOREIGN=1 | 6.81 | 6.8054741 | 0.0111 | 0.0111028 |
| EXCLUDE FOREIGN | 3.24 | 3.2363597 | 0.0763 | 0.0763310 |
Appendix: Full Scripts
Overall F Test:
#Nathaniel Lovin
#Technology Policy Institute
#
#!/usr/bin/env python
from google.cloud import bigquery
import math
import sys
from scipy.stats import f
client = bigquery.Client()
def rsquared(dataset, model):
query = ("SELECT r2_score FROM ml.EVALUATE(MODEL `" + dataset + "." + model + "`)")
query_job = client.query(query)
result = query_job.result()
for row in result:
return row.r2_score
def coefficients(dataset, model_name):
coeffs = []
query = ("SELECT input, weight FROM (ML.FEATURE_INFO(MODEL `" + dataset + "." + model_name + "`) LEFT JOIN ML.WEIGHTS(MODEL `" + dataset + "." + model_name + "`) ON input = processed_input)")
query_job = client.query(query)
result = query_job.result()
for row in result:
coeffs.append(row.input)
return coeffs
dataset = sys.argv[1]
model_name = sys.argv[2]
n = int(sys.argv[3])
coeffs = coefficients(dataset, model_name)
k = len(coeffs)
r2 = rsquared(dataset, model_name)
fstatTop = r2/k
fstatBottom = (1-r2)/(n-k-1)
fstat = fstatTop/fstatBottom
pvalue = f.sf(fstat, k, (n-k-1))
print("F statistic: " + str(fstat))
print("p-value: " + str(pvalue))Run as fscore.py <dataset> <model_name> <size of data>
F-Test for Pre-Existing Models:
#Nathaniel Lovin
#Technology Policy Institute
#
#!/usr/bin/env python
from google.cloud import bigquery
import math
import sys
from scipy.stats import f
client = bigquery.Client()
def rsquared(dataset, model):
query = ("SELECT r2_score FROM ml.EVALUATE(MODEL `" + dataset + "." + model + "`)")
query_job = client.query(query)
result = query_job.result()
for row in result:
return row.r2_score
def coefficients(dataset, model_name):
coeffs = []
query = ("SELECT input, weight FROM (ML.FEATURE_INFO(MODEL `" + dataset + "." + model_name + "`) LEFT JOIN ML.WEIGHTS(MODEL `" + dataset + "." + model_name + "`) ON input = processed_input)")
query_job = client.query(query)
result = query_job.result()
for row in result:
coeffs.append(row.input)
return coeffs
dataset = sys.argv[1]
unrestricted_model = sys.argv[2]
restricted_model = sys.argv[3]
n = int(sys.argv[4])
coeffs = coefficients(dataset, unrestricted_model)
k = len(coeffs)
coeffs2 = coefficients(dataset, restricted_model)
q = k - len(coeffs2)
r2ur = rsquared(dataset, unrestricted_model)
r2r = rsquared(dataset, restricted_model)
fstatTop = (r2ur - r2r)/q
fstatBottom = (1-r2ur)/(n-k-1)
fstat = fstatTop/fstatBottom
pvalue = f.sf(fstat, q, (n-k-1))
print("F statistic: " + str(fstat))
print("p-value: " + str(pvalue))Run as fcompare.py <dataset> <original_model> <restricted_model> <size of dat>
Generating Restricted Models:
#Nathaniel Lovin
#Technology Policy Institute
#
#!/usr/bin/env python
from google.cloud import bigquery
import math
import sys
from scipy.stats import f
client = bigquery.Client()
def create_restricted_model(dataset, data, model_name, dependentVar, coeffs):
query = ("CREATE OR REPLACE MODEL `" + dataset + ".restricted_" + model_name + "` "
"OPTIONS (model_type='linear_reg', input_label_cols=['" + dependentVar + "']) AS "
"SELECT " + ", ".join(coeffs) + " FROM `" + dataset + "." + data + "` WHERE " + " is not NULL and ".join(coeffs) + " is not NULL")
query_job = client.query(query)
result = query_job.result()
def coefficients(dataset, model_name):
coeffs = {}
query = ("SELECT processed_input, weight FROM ML.WEIGHTS(MODEL `" + dataset + "." + model_name + "`)")
query_job = client.query(query)
result = query_job.result()
for row in result:
coeffs[row.processed_input] = {}
coeffs[row.processed_input]['coefficient'] = row.weight
return coeffs
def residuals(dataset, data, model, coeffs, dependentVar):
table_ref = client.dataset(dataset).table(data)
table = client.get_table(table_ref)
original_schema = table.schema
new_schema = original_schema[:]
new_schema.append(bigquery.SchemaField("residual_" + model, "FLOAT"))
table.schema = new_schema
table = client.update_table(table, ["schema"])
assert len(table.schema) == len(original_schema) + 1 == len(new_schema)
regression = ""
for coeff in coeffs.keys():
if coeff != "__INTERCEPT__":
regression += str(coeffs[coeff]['coefficient']) + "*" + coeff + " + "
else:
regression += str(coeffs[coeff]['coefficient']) + " + "
regression = regression[:-3]
query = ("UPDATE `" + dataset + "." + data + "` SET residual_" + model + " = " + regression + " - " + dependentVar + " WHERE residual_" + model + " is null")
query_job = client.query(query)
result = query_job.result()
def ssr(dataset, data, model):
query = ("SELECT SUM(POW(residual_" + model + ", 2)) FROM `" + dataset + "." + data + "`")
query_job = client.query(query)
result = query_job.result()
for row in result:
return row.f0_
def equalCoeffsAdd(dataset, data, combineCoeffs):
table_ref = client.dataset(dataset).table(data)
table = client.get_table(table_ref)
original_schema = table.schema
new_schema = original_schema[:]
new_schema.append(bigquery.SchemaField(combineCoeffs[0] + "_" + combineCoeffs[1], "FLOAT"))
table.schema = new_schema
table = client.update_table(table, ["schema"])
assert len(table.schema) == len(original_schema) + 1 == len(new_schema)
query = ("UPDATE `" + dataset + "." + data + "` SET " + combineCoeffs[0] + "_" + combineCoeffs[1] + " = " + combineCoeffs[0] + "+" + combineCoeffs[1] + " WHERE " + combineCoeffs[0] + "_" + combineCoeffs[1] + " is null")
query_job = client.query(query)
result = query_job.result()
def resetDependentVar(dataset, data, dependentVar, coeffAndScalar):
table_ref = client.dataset(dataset).table(data)
table = client.get_table(table_ref)
original_schema = table.schema
new_schema = original_schema[:]
new_schema.append(bigquery.SchemaField(dependentVar + "_" + coeffAndScalar[0], "FLOAT"))
table.schema = new_schema
table = client.update_table(table, ["schema"])
assert len(table.schema) == len(original_schema) + 1 == len(new_schema)
query = ("UPDATE `" + dataset + "." + data + "` SET " + dependentVar + "_" + coeffAndScalar[0] + " = " + dependentVar + "-" + coeffAndScalar[1] + "*" + coeffAndScalar[0] + " WHERE " + dependentVar + "_" + coeffAndScalar[0] + " is null")
query_job = client.query(query)
result = query_job.result()
dataset = sys.argv[1]
data = sys.argv[2]
unrestricted_model = sys.argv[3]
dependentVar = sys.argv[4]
restrictedDependentVar = dependentVar
coeffsUnrestricted = coefficients(dataset, unrestricted_model)
coeffsToUse = list(coeffsUnrestricted.keys())
coeffsToUse.remove("__INTERCEPT__")
k = len(coeffsToUse)
n = int(sys.argv[5])
args = sys.argv[6:]
q = 0
if (args[0] != "exclude" and args[0] != "set-equal" and args[0] != "specific"):
print("You can exclude variables, set two coefficients equal to each other, or set a coefficient to a specific number")
sys.exit()
if(args[0] == "exclude"):
for i in range(1, len(args)):
if args[i] == "set-equal" or args[i] == "specific":
args = args[i:]
break;
coeffsToUse.remove(args[i])
q += 1
if(args[0] == "set-equal"):
for i in range(1, len(args)):
if args[i] == "specific":
args = args[i:]
break;
removeCoeffs = args[i].split("=")
coeffsToUse.remove(removeCoeffs[0])
coeffsToUse.remove(removeCoeffs[1])
equalCoeffsAdd(dataset, data, removeCoeffs)
coeffsToUse.append(removeCoeffs[0] + "_" + removeCoeffs[1])
q += 1
if(args[0] == "specific"):
for arg in args[1:]:
removeCoeffs = arg.split("=")
coeffsToUse.remove(removeCoeffs[0])
resetDependentVar(dataset, data, restrictedDependentVar, removeCoeffs)
restrictedDependentVar = restrictedDependentVar + "_" + removeCoeffs[0]
q += 1
coeffsToUse.append(restrictedDependentVar)
create_restricted_model(dataset, data, unrestricted_model, restrictedDependentVar, coeffsToUse)
restricted_model = "restricted_" + unrestricted_model
coeffsRestricted = coefficients(dataset, restricted_model)
residuals(dataset, data, unrestricted_model, coeffsUnrestricted, dependentVar)
residuals(dataset, data, restricted_model, coeffsRestricted, restrictedDependentVar)
ssrur = ssr(dataset, data, unrestricted_model)
ssrr = ssr(dataset, data, restricted_model)
fstatTop = (ssrr - ssrur)/q
fstatBottom = (ssrur)/(n-k-1)
fstat = fstatTop/fstatBottom
pvalue = f.sf(fstat, q, (n-k-1))
print("F statistic: " + str(fstat))
print("p-value: " + str(pvalue))Run as fgenerate.py <dataset> <data> <unrestricted model name> <dependent variable of unrestricted model> <size of data> <”exclude” if any terms are being excluding> <terms being excluded> <”set-equal” if any terms are being set equal to each other> <each pair of terms being set equal to each other, each variable name in the pair separated by an equal sign (as in “gear_ratio=weight”> <”specific” if any terms are being set to specific values> < each term being set to a specific value, followed by the value it’s being set to, separated by an equal sign, as in “foreign=1”>

